


(R. Beß, J. Denzler, V. Fischer,
J. Hornegger,
P. Kral,
T. Merz, W. Obermayer,
D. Paulus,
F. Popp
)
Auch im Jahr 1995 wurden die im Bereich der Bildanalyse bestehenden Projekte und Aufgaben fortgesetzt und teilweise fertiggestellt. In neuen Bereichen wurden die Vorarbeiten aufgenommen, um dem Gesamtziel näherzukommen, das in einer wissensbasierten Analyse von Bilddaten besteht. Die Verarbeitung in einem geschlossenen Kreislauf von Sensorik und Aktorik erweitert dieses Ziel. Die Ermittlung von 3D-Information, die Erkennung von Objekten und deren Lage, die schnelle Auswertung von Wissen über das Problemfeld und gezielte Veränderungen des Aktors, um die gewünschten Ergebnisse schneller oder genauer zu erhalten, dienen der Lösung von Teilproblemen.
Der grundlegende Versuchsaufbau für die Projekte der Bildanalyse besteht aus einer monokularen Kamera, die an der Hand eines Roboters montiert ist und dadurch im Arbeitsraum des Roboters frei positioniert werden kann, und einem rechnergesteuerten Stereogestell mit hochwertigen Farbkameras, welche die Szene überwachen. Zum Roboter zählen zudem ein Drehteller und ein Linearschlitten. Drei rechnergesteuerte Schwenk-Neige-Systeme mit Farbkameras sowie ein Stereo-Kopf mit Schwenk-Neige-Vergenz-Steuerung und Farbkameras vervollständigen die Möglichkeiten zur Bildaufnahme. Ein neuer Bildeinzugsrechner vom Typ SGI Onyx gestattet die Digitalisierung eines Bildkanals mit 25 Bildern pro Sekunde und voller PAL Auflösung, und die Übertragung ohne Prozessorlast direkt in den Hauptspeicher. Die bewegliche Kamera ermöglicht es, ein Objekt aus verschiedenen Blickwinkeln aufzunehmen, so daß die Oberfläche vollständig erfaßt werden kann. Dies ist insbesondere dann notwendig, wenn ein dreidimensionales Modell des Objektes gebildet werden soll, oder eine einzelne Ansicht nicht ausreicht, um ein komplexes Objekt zu erkennen.
Eine erhebliche Erweiterung der Arbeitsplätze für Studenten erfuhr der Lehrstuhl durch eine Spende der Firma HP, die im Rahmen eines Programms zur Förderung der Lehre an solche Universitäten vergeben wurde, die sich im Bereich der Bildverarbeitung und Multi-Media besonders engagieren. Europaweit wurden drei Lehrstühle, weltweit zehn Universitäten ausgewählt.
Die Projekte der Bildanalyse gliedern sich in die folgenden Teilaufgaben, auf die im folgenden im Detail eingegangen wird.
In allen Entwicklungen wird auf eine Austauschbarkeit und Wiederverwertbarkeit der Module größter Wert gelegt, wofür inbesondere die Mechanismen der objektorientierten Programmierung eingesetzt werden.
Auf dem Gebiet der Echtzeitbildverarbeitung wurde das Projekt zur Echtzeitobjektverfolgung weiter fortgeführt. Ein Objekt, das sich auf einem Schienenkreis bewegt, wird in Echtzeit mit dem Roboter verfolgt. Die Objektverfolgung basiert auf den sogenannten aktiven Konturmodellen (Snakes), mittels derer rein datengetrieben Konturen in Bildern lokalisiert und extrahiert werden.
Für homogenen Hintergrund wurde bereits gezeigt, daß eine robuste Objektverfolgung in einem geschlossenen Regelkreis aus Bildaufnahme und Roboter-/Kamerasteuerung (Aktion) in Echtzeit möglich ist [7, 8]. Bei heterogenem Hintergrund, d.h. starken Kanten in der Nähe des bewegten Objekts, oder Verdeckungen muß der datenbasierte Ansatz um eine Prädiktion erweitert werden, die während der Verfolgung Informationen über die Bewegungsrichtung des Objekts sammelt und somit die Position im nächsten Bild vorhersagen kann.
Ein Problem bei der datenbasierten Prädiktion aktiver Konturen besteht darin, daß aufgrund der 2D-Konturpunkte eines 3D-Körpers keine Aussage über die tatsächliche Form des Körpers getroffen werden kann, da zu einer 2D-Kontur mehrere Objekte existieren, deren perspektivische Projektion diese Kontur erzeugen. Erschwert wird eine solche Prädiktion beim Erscheinen von Kanten in der Nähe der Kontur, da in diesem Fall nur schwer zu entscheiden ist, ob diese neue Kante zum Hintergrund gehört, oder eine durch Drehung neu erscheinende Objektkante ist.
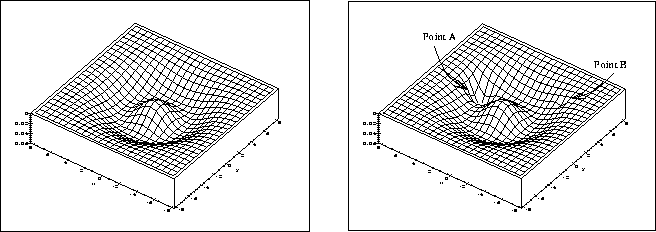
Abbildung:
Prinzip der Gewichtung der Vorhersage in der Energiefunktion: Die Vorhersage
des Punktes A hat eine große Gewichtung, während die geringe
Gewichtung der Vorhersage des Punkts B erlaubt, das tatsächliche
Minimum in der Energiefunktion zu erreichen.
Bei aktiven Konturen sind drei prinzipielle Prädiktionmechanismen möglich. Eine Prädiktion für aktive Konturen kann zum einen implizit, d.h. innerhalb der Energieminimierung der aktiven Kontur stattfinden (Modellierung der zeitlichen Kohärenz in der Energiefunktion), oder durch eine Prädiktion unabhängig von der eigentlichen Energieminimierung (explizite Prädiktion). Im letzteren Fall besteht das Prinzip darin, die Startposition der Konturpunkte vor Beginn der Energieminimierung in die Nähe des zu erreichenden Minimums zu legen. Ein einfaches Beispiel ist die Extrapolation der Konturpunkte, beziehungsweise im allgemeinen die Parameterschätzung eines Bewegungsmodells. Das Prinzip der Modellierung der zeitlichen Kohärenz in der Energiefunktion besteht darin, Positionen von Konturpunkten im Rahmen einer Energieminimierung mit einem niedrigen Potential zu versehen, wenn sie mit der zeitlichen Kohärenz der Bewegung des Konturpunktes konform sind (siehe Bild 1). Dazu kann beispielsweise auf den Formalismus der Variationsrechnung mit Nebenbedingungen zurückgegriffen werden. Eine dritte Form besteht in einer Kombination aus impliziter und expliziter Prädiktion, bei der zuerst nach einer guten Startposition gesucht und anschließend das Potential in der Nähe der Startposition in der Energieminimierung erniedrigt wird.
Im Rahmen der beschriebenen Untersuchungen wurde eine explizite Prädiktion basierend auf einem 2D-Bewegungsmodells der Konturpunkte und einer Parameterschätzung über Kalman-Filter realisiert. Damit wurde gezeigt, daß Fehler bei der Verfolgung durch Teilverdeckungen des Objekts und starken Hintergrundkanten erheblich reduziert werden konnten. Der Einsatz des Bildeinzugsrechners führte zu einer weiteren Leistungssteigerung des Gesamtsystems. Bei einer Anwendung der Algorithmen auf Bildfolgen aus dem Bereich des Straßenverkehrs (Verfolgung von Fahrzeugen) konnte die Allgemeinheit des realisierten Ansatzes gezeigt werden.
Die weiteren Arbeiten konzentrieren sich auf die Implementierung einer impliziten Prädiktion, einer direkten Kopplung von Energieminimierung und Parameterschätzung über Kalman-Filter, sowie auf eine Schätzung der 3D-Form und 3D-Bewegung des zu verfolgenden Objekts.
Im Sonderforschungsbereich 182 ``Multiprozessor- und Netzwerkkonfigurationen'' liegt der Schwerpunkt der Arbeiten zur Echtzeitanalyse auf der Untersuchung von Möglichkeiten zur Parallelverarbeitung in der wissensbasierten Bildanalyse. Ergänzend werden auch hier die oben erläuterten Möglichkeiten der Verarbeitung in einem geschlossenen Kreislauf von Sensor und Aktor untersucht. Diese Problematiken werden anhand zweier ausgewählter Teilaspekte, der Extraktion von Tiefeninformation aus monokularen Bildfolgen und der Wissensverarbeitung in semantischen Netzen bearbeitet.
Ansätze zur Tiefengewinnung aus einer einzelnen Ansicht eines Objektes sind für eine Anzahl interessanter Anwendungen nicht ausreichend, so zum Beispiel, wenn komplexe Objekte erkannt werden müssen, oder wenn ein Modell des gesamten Objektes gebildet werden soll.
Daher ist das Ziel der durchgeführten Arbeiten zur Tiefengewinnung die Berechnung von Tiefenbildern der möglichst gesamten Oberfläche eines Objektes. Die dazu notwendige gezielte Aufnahme verschiedener Ansichten eines Objektes wird durch die Kamera ermöglicht, die an der Hand eines Roboters befestigt ist. Die Position dieser Kamera wird durch eine Greifer-Kamera-Kalibrierung [42, 43] bestimmt.
Zur Berechnung von Tiefendaten aus einer Bildfolge wurden zwei Wege verfolgt: einerseits die Übertragung und Erweiterung bereits vorhandener Algorithmen zur Tiefenbestimmung aus Stereobildern, andererseits die Entwicklung von Verfahren speziell zur Tiefenbestimmung aus Bildfolgen.
Bei den Stereoverfahren werden die Bildpunkte eines 3D-Punktes in zwei Teilbildern gesucht. Aus der Verschiebung der Bildpunkte zwischen den Teilbildern, wird bei bekannter Kameraposition die Lage des 3D-Punktes im Raum berechnet. Das wesentliche Problem bei diesen Verfahren ist das Zuordnungsproblem: in den beiden Teilbildern muß erkannt werden, welche Bildpunkte denselben 3D-Punkt abbilden.
Von den Verfahren zur Lösung des Zuordnungsproblems ist die Zuordnung von geometrischen Primitiven wie Linienstücken am zuverlässigsten und genauesten. Fehler treten hier fast ausschließlich dann auf, wenn viele ähnliche, kurze Lininenstücke im Bild gefunden werden oder wenn ein Linienstück nur in einem Bild gefunden wird. Im Gegensatz zu anderen Verfahren -- wie zum Beispiel den korrelationsbasierten Verfahren -- wird allerdings Tiefe nur an wenigen Punkten des Objektes -- eben den Linien -- bestimmt.
Im Berichtszeitraum wurde ein Verfahren realisiert, das die Vorteile der beiden Ansätze verbindet. Dazu wurde die Zuordnung geometrischer Primitive mit einem Blockvergleichsverfahren kombiniert und zur Verarbeitung von Farbbildern modifiziert.
Die Verarbeitung von Farbbildern hat zwei wesentliche Vorteile. Zum einen wird durch Einbeziehung der Farbinformation die Zuverlässigkeit der Liniendetektion erhöht; es werden weniger Störungen als Linien interpretiert und weniger Linien mit schwachem Kontrast übersehen, zum anderen können zusätzliche Linieneigenschaften wie der Farbunterschied entlang einer Linie eingesetzt werden, um die richtige Wahl unter ähnlichen Linien zu unterstützen.
Trotzdem ist zunächst der Anteil fehlerhafter Zuordnungen relativ hoch, wenn die Stereoverfahren auf Bildfolgen statt auf Aufnahmen einer Stereokamera angewendet werden. Der Grund liegt in dem hohen Winkelunterschied zwischen zwei Bildern der Bildfolge: er beträgt hier etwa 21 Grad gegenüber weniger als einem Grad in einer Aufnahme der Stereokamera. Dadurch treten in wesentlich höherem Maße Verdeckungen auf und damit Merkmale, die nur in einem Bild sichtbar sind, für die also gar keine korrekte Zuordnung existiert. Bei einer Verringerung des Aufnahmewinkels auf die Hälfte vervierfacht sich jeweils die Anzahl der Aufnahmen und damit der Berechnungsaufwand. Im Berichtszeitraum wurde daher statt dessen die Robustheit der Algorithmen gegenüber Verdeckungen wesentlich erhöht. Dazu sind zwei Ansätze realisiert:
Durch Verwendung von Geraden-Kreisbogen-Sequenzen anstelle der bisher ausschließlich untersuchten Geradensequenzen wird bei gleichbleibender Genauigkeit die Anzahl der Linienstücke in der Approximation im Schnitt um mehr als 40% reduziert. Durch relativ grobe Annäherung der im Bild gefundenen Linien mit einer maximalen Abweichung von mehreren Pixeln wird die Anzahl der Linienstücke nochmals um mehr als 20% verringert; dabei wird die Abbildung zwischen den Linien und ihrer Approximation genutzt, um die Disparität auf den ursprünglichen Linien zu berechnen, so daß der Approximationsfehler keinen Genauigkeitsverlust verursacht.
Die geringere Anzahl der Linienstücke führt zu einer entscheidenden Verbesserung der Zuordnungsergebnisse, da vor allem kurze Linienstücke eliminiert werden, die sehr viele ähnliche Zuordnungen erlauben.
Der anschließende Blockvergleichsalgorithmus nutzt die berechneten Disparitätswerte als Startwerte und liefert als Ergebnis die Disparitäten der im Stereobild sichtbaren Ansicht des Objektes und damit nach einer einfachen Umrechnung ein Tiefenbild dieser Ansicht.
Da die Position der Kamera innerhalb eines globalen Koordinatensystems bei allen Aufnahmen bekannt ist, können die Tiefenbilder verschiedener Ansichten im Prinzip direkt zu einer vollständigen Tiefenkarte des Objektes zusammengesetzt werden. Auf Grund von Ungenauigkeiten in der Kalibrierung kann jedoch die durchschnittliche Verschiebung von Tiefenwerten des gleichen Objektpunktes bis zu 24 mm betragen. Zur Bestimmung der Transformation zwischen den einzelnen Tiefenbildern wurde daher ein Registrierungsschritt entwickelt, der den relativen Fehler zwischen den Tiefenbildern auf weniger als 2 mm reduziert. Dieses Verfahren hat den wesentlichen Vorteil, daß kein 3D-Zuordnungsschritt durchgeführt werden muß, sondern analytisch der Zusammenhang zwischen den Tiefenwerten in geschlossener Form bestimmt werden kann. Bild 2 zeigt zwei von sechs Tiefenbildern und das Ergebnis der Registrierung.

Abbildung 2: Tiefenbilder, Ergebnis der Registrierung.
Die Portierung der am Lehrstuhl für Mustererkennung entwickelten Programmierumgebung zur Musteranalyse auf das im Sonderforschungsbereich 182 entwickelte Multiprozessorsystem MEMSY wurde weitergeführt. Laufzeitmessungen der bereits parallelisierten Blockvergleichsalgorithmen bestätigten den erwarteten, nahezu linearen Speedup.
Eine Möglichkeit zur Ermittlung von Tiefe bietet die aktive Veränderung der Kameraeinstellung oder deren Position. Durch ein erweitertes Kameramodell für Zoomkameras lassen sich die am Lehrstuhl vorhandenen Aufnahmegeräte geeignet beschreiben, so daß für beliebige Brennweite-, Fokus- und Blendenkombinationen das Lochkameramodell seine Gültigkeit behält. Je nach verwendeter Kamera sind dazu eine unterschiedliche Anzahl von Kalibrierungen erforderlich.

Abbildung 3: Tiefenermittlung mit einer Zoomkamera
Während die Veränderung der Bilder bei einer rein rotatorischen Bewegung des Geräts keinen Rückschluß auf die Entfernung der beobachteten Objekte gestattet, läßt sich durch eine Kombination von Kameraschwenks und Veränderung der Brennweite Tiefe berechnen. Wird die Positionsänderung kontinuierlich durchgeführt, so entfällt die aufwendige Zuordnung von Bildpunkten des einen Bildes zum anderen, wie sie beispielsweise für Stereoverfahren charakteristisch ist. Bild 3 zeigt links und rechts zwei Aufnahmen einer Serie mit veränderter Brennweite; das mittlere Bild zeigt die Trajektorien, aus denen ersichtlich ist, daß sich die Brennweite nicht linear mit den Schrittmotorwerten ändert. Zur Suche interessanter Punkte in der Bildserie, die sich durch die Veränderung der Brennweite und durch Schwenks ergibt, wird neuerdings Farbinformation verwendet. Die Verfahren werden an die am Lehrstuhl neu vorhandenen aktiven Kamerasysteme angepaßt, wozu insbesondere eine einheitliche Programmierschnittstelle in dem am Lehrstuhl verwendeten objektorientierten Programmiersystem erarbeitet wurde.
Die (ebenfalls) im Rahmen des Sonderforschungsbereichs 182 ``Multiprozessor- und Netzwerkkonfigurationen'' durchgeführten Untersuchungen zur Parallelverarbeitung in der wissensbasierten Musteranalyse wurden fortgesetzt. Als Untersuchungsgegenstand diente hierbei wie auch in den vergangenen Jahren das Erlanger semantische Netzwerksystem ERNEST, eine auf dem Formalismus der semantischen Netzwerke aufbauende Systemschale zur Realisierung von Musteranalysesystemen, die sowohl im Bereich des Bildverstehens als auch zum automatischen Verstehen gesprochener Sprache eingesetzt wird.
Der für die Belange der parallelen Musteranalyse entwickelte Kontrollalgorithmus [12] faßt die Erzeugung einer symbolischen Szenenbeschreibung als Optimierungsproblem auf, bei dem eine problemabhängige, heuristische Kostenfunktion minimiert wird; hierzu kommen verschiedene kombinatorische Optimierungsverfahren wie beispielsweise genetische Algorithmen oder der Sintflutalgorithmus zum Einsatz. Konzentrierten sich die Arbeiten bislang auf die Entwicklung und Evaluierung paralleler Inferenzmechanismen und die Parallelisierung der übergeordneten Optimierungsverfahren zur Behandlung konkurrierender Zwischenergebnisse des Analyseprozesses, so lag der Schwerpunkt der Arbeiten nunmehr auf der Verbesserung der ``Any-Time''-Fähigkeit des entwickelten Ansatzes, unter welcher die schnelle Berechnung suboptimaler Interpretationen und deren iterative Verbesserung verstanden wird. Bild 4 illustriert dies an einem Beispiel aus der in der Vergangenheit untersuchten Interpretation von Bildfolgen natürlicher Straßenverkehrsszenen, deren Ziel die Identifikation der freien Fahrbahn sowie die Beschreibung der Fahrbahnmarkierung war.

Abbildung: Any-Time-Kontrollalgorithmus für semantische
Netze: Straßenverkehrsszene (links) und Interpretation nach 30, 85, und 139
Iterationen.
Die Notwendigkeit zu dem im folgenden skizzierten Vorgehen ergibt sich unmittelbar aus der Tatsache, daß der Speedup für die Parallelisierung der im sematischen Netzwerk ablaufenden Inferenzprozesse bereits bei der Verwendung weniger Prozessoren gesättigt ist und ein verbessertes ``Any-Time''-Verhalten somit durch eine stärkere Fokussierung der Analyse auf relevante Teilinterpretationen erreicht werden muß. Daher wurde das bereits aus dem graphbasierten Kontrollalgorithmus der ERNEST-Systemschale bekannte Vorgehen der vorrangigen Instantiierung obligatorischer Konzepte und die daran anschließende Behandlung optionaler Konzepte auf das in der Vergangenheit entwickelte massiv-parallele Instantiierungsschema, den Attributflußgraphen, übertragen. Neben der durch diese Dekomposition erzielten Reduktion der Suchraumgröße erwies sich insbesondere die modellgetriebene Propagierung von Einschränkungen als vorteilhaft für eine Verkürzung der Iterationsdauer, da hierdurch einerseits zahlreiche Knoten des Attributflußgraphen von der Berechnung ausgeschlossen werden können und andererseits die Zahl der zu verarbeitenden Segmentierungsergebnisse reduziert werden kann.
Die Tragfähigkeit der in der Vergangenheit entwickelten Methoden zur Parallelverarbeitung in semantischen Netzen und insbesondere der hier vorgestellten Erweiterungen wird auch durch die begonnene Übertragung des Ansatzes auf die Steuerung der linguistischen Analyse des Spracherkennungssystems EVAR demonstriert [11], die an anderer Stelle in diesem Bericht dokumentiert ist.
Als Alternative zur strukturellen Beschreibung von Objektmodellen, wie sie mit semantischen Netzen möglich ist, gewinnen statistische Objetmodelle in der Bildanalyse zunehmend an Bedeutung. Der Ansatz zur statistischen Objekterkennung [44] wurde mit dem Ziel weiterverfolgt, einen Bayes-Klassifikator für die Identifikation und Lokalisation von 3D-Objekten zu entwickeln. Die wesentlichen Fortschritte sind dabei in einer abstrakten statistisch mathematischen Beschreibung von Objektmerkmalen in der Bildebene, in der Erweiterung der Verfahren auf beliebige Merkmale sowie in einer objektorientierten Realisierung der Modelldichten und der damit verbundenen Klassifikations- und Lokalisationsverfahren zu sehen. Das so entstandene Objekterkennungssystem eignet sich sowohl für die 3D- als auch die 2D-Objekterkennung [16].
Im Gegensatz zu rein geometrisch motivierten Ansätzen entspricht ein Objektmodell im statistischen Kontext einer Wahrscheinlichkeitsdichte, die gleichzeitig die Projektion vom Modell- in den Bildraum, Sensorrauschen, den Einfluß der Beleuchtung und Segmentierungsfehler modelliert. Eine Modelldichte wird durch unterschiedliche Parameter charakterisiert: Merkmalspezifische Parameter beschreiben das statistische Verhalten einzelner Objektmerkmale, lagespezifische Parameter dienen zur Repräsentation der Freiheitsgrade, die Objekte bezüglich ihrer Lage im Raum innehaben. Die Zuordnung zwischen Bild- und Modellmerkmalen sowie relationale Zusammenhänge werden dabei durch diskrete Zufallsgrößen erfaßt. Eine Modelldichte ist damit eine Verbundwahrscheinlichkeitsdichte, die verschiedene statistische Prozesse in einem einzigen mathematischen Term vereint.
Durch spezielle Wahl der beteiligten Komponenten einer Modelldichte und durch die Festlegung statistischer Abhängigkeiten für die Zuordnung oder Relationen lassen sich unterschiedliche Modelldichten konstruieren und bekannte Modellierungsansätze ableiten. So führt ein Verzicht auf die integrierte Transformation von Merkmalen und der Einsatz statistisch unabhängiger Zuordnungen zu Mischverteilungen; aus der Forderung nach statistischer Abhängigkeit erster Ordnung für die Zuordnungen entstehen die in der Spracherkennung etablierten Hidden-Markov-Modelle.
Die theoretischen Ergebnisse zeigen, daß sich bereits eingesetzte statistische Modelle in den entwickelten Formalismus einbetten lassen und sich zudem ein für die Objekterkennung geeignetes statistisches Modell ableiten läßt. Statistische Objektmodelle sowie ein Teil der in der Spracherkennung verwendeten statistischen Modelle lassen sich letztlich auf dieselben Grundideen zurückführen.
Für die Objektmodellierung -- sei es zu Zwecken der 2D- oder 3D-Objekterkennung -- erweisen sich Mischverteilungen mit integrierter Merkmaltransformation als geeignet. Während der Trainingsphase werden die Parameter der Modelldichte aus Beispielaufnahmen geschätzt, die ein Objekt aus unterschiedlichen Blickrichtungen zeigen. Da die Modellgenerierung bei unbekannter Zuordnung von Bild- und Modellmerkmalen erfolgen muß, wird hierfür der Expectation-Maximization-Algorithmus eingesetzt. Die Klassifikation basiert dann auf der Bayes-Entscheidungsregel, deren Anwendung durch die Einführung von Modelldichten erst ermöglicht wird. Zuvor müssen jedoch die Lageparameter des Objekts geschätzt werden, wobei zur Lösung dieses Problems probabilistische Suchverfahren zu besseren Ergebnissen führten, als dies mit deterministischen Gittersuchverfahren der Fall war.
Modelldichten können für verschiedene Merkmale definiert werden, und die Algorithmen zum Training und zur Klassifikation weisen viele Gemeinsamkeiten auf, was eine objektorientierte Implementierung nahelegt. Die Realisierung der entwickelten Verfahren wurde deshalb in der Programmiersprache C++ vorgenommen, wobei die Programme derzeit 114 Klassen und 117 Anwendungsroutinen umfassen. Die aktuell erzielten Erkennungsraten belaufen sich auf 93% für 2D- und 68% für 3D-Objekte, wobei sich jeweils vier Objekte in der Modelldatenbasis befinden. Ein Beispiel für ein lokalisiertes 3D-Objekt zeigt Bild 5.

Abbildung 5: Eine 3D-Szene, die berechneten Eckpunkte und
das Ergebnis der Lokalisation
Die erfolgversprechenden Erfahrungen mit statistisch basierten Verfahren zur Objekterkennung haben dazu geführt, daß sich zwei Stipendiaten mit der Problematik der statistischen Objekterkennung und Szenenmodellierung in dem von der Deutschen Forschungsgemeinschaft geförderten Graduiertenkolleg Dreidimensionale Bildanalyse und -synthese beschäftigen werden. Der Förderungszeitraum beginnt mit dem 1. Januar 1995 und beträgt insgesamt drei Jahre.
Mitte des Jahres begann ein neues Projekt zur automatischen Materialprüfung auf interferometrischer Basis. Das von der DFG geförderte Projekt wird gemeinsam mit dem Bremer Institut für Angewandte Strahltechnik (BIAS) durchgeführt, welches auch den notwendigen optischen und mechanischen Aufbau zur Verfügung stellt. Aufgabe des Prüfsystems ist die automatische Klassifikation von Materialfehlern, die sich sowohl auf, als auch unter der Oberfläche befinden können, hinsichtlich ihres Typs, ihrer Lage und ihrer Ausdehnung.
Mittels Interferometrie als bildgebendem Verfahren ist es möglich, Oberflächenverformungen belasteter Prüfobjekte aus beobachteten Interferenzmustern zu bestimmen (intensitätsbasierte Interferogrammauswertung). Bei einer Belastung des Prüfobjektes bewirken Materialfehler eine signifikante lokale Oberflächenverformung und führen daher zu Irregularitäten in Streifenverläufen (Bild 6 links).
Wesentliche Ursachen für die Nichtverfügbarkeit automatischer Prüfsysteme auf interferometrischer Basis sind die Vielfalt und die vorhandenen Mehrdeutigkeiten der Interferenzmuster sowohl von fehlerfreien als auch fehlerbehafteten Objekten. Da die Ausprägung der Muster durch zahlreiche Einflußfaktoren wie Material, Konstruktion, Einspannung, Belastung und Krafteinwirkung signifikant beeinflußt wird, ist eine starre Erkennungsstrategie auf der Grundlage einer klassifizierten Stichprobe nur dann möglich, wenn die Randbedingungen des Prüfprozesses in einer für die Praxis unzulässigen Weise eingeschränkt werden.
Es wird daher eine flexible Prüfstrategie verfolgt, die das vorhandene Wissen über den Musterentstehungsprozeß mit den Möglichkeiten moderner Berechnungsverfahren der experimentellen Festkörpermechanik über einen iterativen Bildsynthese- und Bildanalyseprozeß bei gezielter Laständerung verbindet. Die prinzipielle Vorgehensweise sieht vor, das aufgenommene Interferogramm eines definiert belasteten Prüfobjekts mit einem synthetischen, aus einem Strukturmodell des Prüfobjekts berechneten Interferogramm zu vergleichen. Das Strukturmodell entsteht aus der bekannten Struktur des fehlerfreien Prüfobjekts bei gegebener Belastung und einem angenommenen Materialfehler. Ist die Fehlerhypothese richtig, so stimmen die Interferenzmuster auch bei verschiedenen Belastungen überein. Ist dies nicht der Fall, so werden weitere Vergleiche mit einer neuen Fehlerhypothese durchgeführt.
Für den Mustervergleich ist es sinnvoll, zunächst charakteristische Merkmale wie Interferenzstreifendichte und -krümmung zu extrahieren. Am Lehrstuhl wurde damit begonnen, aus einem Interferogramm eine linienbasierte Beschreibung zu generieren (Bild 6 rechts). Das Augenmerk liegt dabei im Gegensatz zu den meisten existierenden Verfahren zur Interferogrammauswertung besonders auf robuster, nicht interaktiver und schneller Segmentierung. Es werden derzeit Verfahren untersucht, die Streifenkanten- oder Streifenextrema entweder direkt auf dem Grauwertbild oder auf einem zuvor binarisierten Bild verfolgen.

Abbildung: Links: Interferogramm eines fehlerbehafteten
Prüfobjekts (sogenanntes ``Auge''). Rechts: Darstellung der Streifenkanten.
Die seit Jahren fruchtbar durchgeführte Partnerschaft mit der Universität Ljubljana (Slowenien) wurde mit einem Aufenthalt von Professor S. Kovacic fortgesetzt, der sich mit der aktiven Kamerakontrolle beschäftigte. Professor A. Krzyzak (Concordia Univerität, Montreal, Canada) war zwei Monate am Lehrstuhl als Gast und untersuchte die Verwendung neuronaler Netze in der Bilderkennung.
Bildverarbeitung und -analyse sind von zentraler Bedeutung in multimedialen Anwendungen. Bildübertragung und Bildcodierung mit niedrigen Bandbreiten erfordern neue Verfahren. Fraktale Bildkompression und Wavelet-basierte Codierung waren Gegenstand einer Untersuchung, die in Zusammenarbeit mit der Universität Kosice von Herrn Kral durchgeführt wurden.
Externe Anwendungen erfuhr das Bildanalysesystem in der fortgesetzten Kooperation mit Instituten der Medizinischen Fakultät. In einer Kooperation mit der Poliklinik für Zahnerhaltung und Parondontologie der Universität Erlangen-Nürnberg wird Bildanalyse für die Fertigung von Zahnersatz eingesetzt [33]. In der Polyklinik für Hals-, Nasen- und Ohrenkranke der Universität Erlangen-Nürnberg werden Möglichkeiten gesucht, Gesichtsdeformitäten zu korrigieren. In einer gemeinsamen Studie wurde untersucht, wie Bildfolgen von Patienten verwendet werden können, um die äußerlich sichtbaren Unregelmäßigkeiten automatisch in ein medizinisches Schema einzuordnen. Thermographische Bildfolgen der Haut nach einer künstlich erzeugten Erregung werden klinisch erfaßt, um Aussagen über die Reizleitung zu machen. Dieses Thema wird in Zusammenarbeit mit dem Lehrstuhl für Physiologie I bearbeitet. Innerhalb dieser Untersuchungen gewährleistet die morphologische Wasserscheidentransformation aussagekräftige Ergebnisse [31]. In einer neu begonnenen Kooperation mit der Augenklinik wird weiterhin geprüft, wie sich Gefäße in Retinascans automatisch detektieren lassen.