


(W. Eckert, W. Fentze, J. Fischer,
V. Fischer,
F. Gallwitz, J. Haas, S. Harbeck,
A. Kießling, R. Kompe,
M. Mast, E. Nöth, A. Raab,
E.G. Schukat-Talamazzini)
Die inhaltlichen Schwerpunkte der Forschungsaktivitäten zur Sprachverarbeitung bilden das maschinelle Erkennen und Verstehen gesprochener Äußerungen sowie Fragestellungen der Dialogkontrolle. Die Arbeiten im Berichtsjahr konzentrierten sich auf die Untersuchung spezieller Eigenschaften von über Kurzwelle übertragenen Sprachsignalen sowie auf die (Weiter-)entwicklung prototypischer Sprachdialogsysteme zweier Anwendungsbereiche: der InterCity-Fahrplanauskunft und der multilingualen Terminabsprache.
Für die Zugauskunftdomäne wurde im von der EU geförderten SUNDIAL-Projekt ein Laborprototyp eines sprecherunabhängigen Systems zur Mensch-Maschine-Kommunikation entwickelt. Eine Weiterentwicklung dieses Prototyps wurde im Berichtsjahr im Rahmen eines DFG-Projektes einem umfangreichen Feldtest unterworfen. Darüberhinaus wurde im vergangenen Jahr im Rahmen eines von der EG finanzierten Copernicus Projektes eine Erweiterung des EVAR-Auskunftssystems in Richtung auf Multilingualität und Multifunktionalität gestartet. Das Projekt SQEL (Spoken Queries in European Languages) wird vom Lehrstuhl zusammen mit der Universität in Ljubljana, Slowenien (Prof. Pavesic), der Universität in Pilsen, Tschechien (Prof. Matousek) und der Technischen Universität in Kosice, Slowakei (Prof. Krokavec) durchgeführt. Ziel des Projektes ist eine Erweiterung in Hinblick auf ein System, welches Fragen in jeder der vier Sprachen zu unterschiedlichen Anwendungen (z.Zt. Zugauskunft und Flugauskunft) verarbeiten kann. Bild 7 zeigt die Architektur des SQEL-Gesamtsystems, das eine Erweiterung des EVAR-Auskunftssystems darstellt. Die Arbeiten im vergangenen Jahr konzentrierten sich auf die Erstellung von Erkennern in den drei slawischen Sprachen.
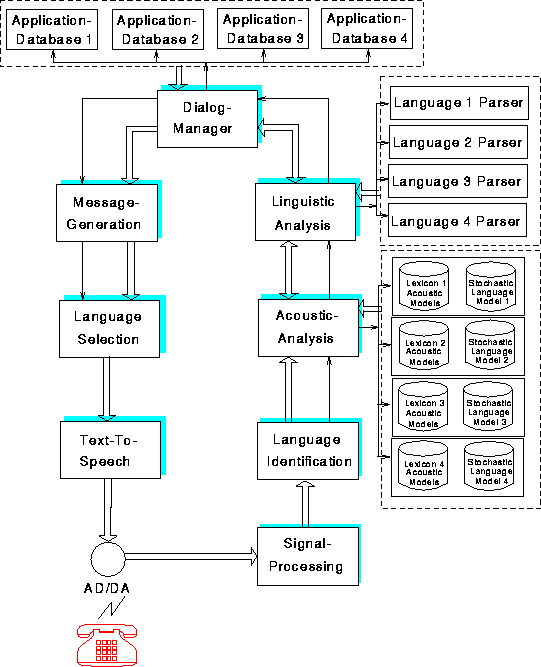
Abbildung: Architektur des SQEL-Gesamtsystems
Eine Erweiterung der Forschungsaktivitäten auf dem Gebiet
der informationsabfragenden Mensch-Maschine-Dialoge
ist
die Entwicklung eines Dialogsystems mit
Any-Time-Fähigkeit und verbessertem Echtzeitverhalten
im Rahmen eines ``Real World Computing'' (RWC) Projektes,
welches von
MITI gefördert wird.
gefördert wird.
Das zweite Anwendungsfeld (multilinguale Terminabsprache) ist durch die Einbindung des Lehrstuhls (3 Mitarbeiter/innen) in das BMBF-geförderte VERBMOBIL-Vorhaben bedingt. Projektpartner sind 32 Arbeitsgruppen aus mehreren Universitäten, Großforschungseinrichtungen und Firmen. Im VERBMOBIL-Vorhaben ist ein portables Übersetzungsgerät zu entwickeln, welches auf Konferenzen mit Teilnehmern unterschiedlicher Muttersprachen die Dolmetschfunktion übernimmt. Für die erste Projektphase wird von einem Benutzer ausgegangen, der die gemeinsame Tagungssprache (Englisch) zumindest passiv beherrscht und das Übersetzungssystem nur in kritischen Phasen des Dialogs einschaltet, um den Kommunikationserfolg durch Benutzung seiner eigenen Muttersprache abzusichern. Das Thema der multilingualen Verhandlung soll sich im Rahmen geschäftlicher Terminabsprachen bewegen.
Eher anwendungsunabhängig ist ein Projekt, welches im vergangenen Jahr in Kooperation mit der Firma MEDAV (Uttenreuth) begonnen wurde. In diesem Projekt geht es um den Einsatz von Sprachtechnologie auf Kurzwellensignalen. Besondere Anforderungen an das Projekt ergeben sich aus dem Szenario der Kurzwelle. So liegen i.a. Signale schlechter Qualität mit variierendem Signal-Rauschverhältnis vor. Die vorhandenen Störungen im Kurzwellenbereich sind vielfältiger Art: Knacken, Rauschen, Schwundeffekte (Fading), Übersprechen und auch Kombinationen dieser Störungen. Um entwickelte Methoden einfacher auf derartigen Signalen zu testen, wurde ein Simulator für diesen Kanal konstruiert, der aus vorhandenen Signalen guter Qualität gestörte Signale erzeugen kann, die der Kurzwelle sehr ähnlich sind.
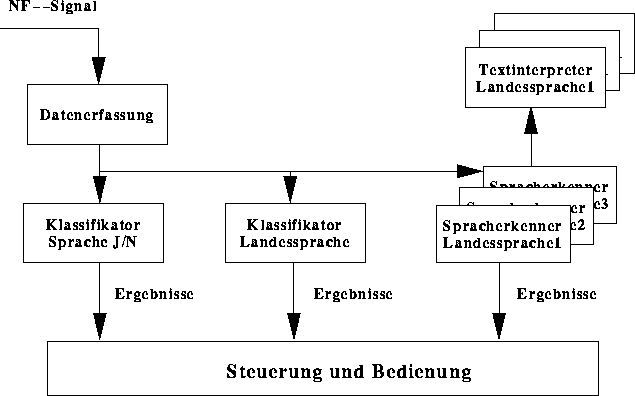
Abbildung: Aufbau des Gesamtsystems für die Analyse von
Kurzwellensignalen
Neben der Konstruktion eines Kanalsimulators geht es vor allem um die Entwicklung von Algorithmen in den Bereichen der Sprache-Nichtspracheklassifikation, der Landessprachenklassifikation und der Worterkennung sowie um Topic Spotting Verfahren (siehe Bild 8). Mit Hilfe der Sprache-Nichtspracheklassifikation soll möglichst in kurzer Zeit entschieden werden, ob es sich bei einem Signal um gesprochene Sprache handelt oder ob eher Datenübertragung, Rauschen oder sonstiges vorliegt. Die Landessprachenklassifikation (siehe [39]) soll ebenfalls in möglichst kurzer Zeit aus einem Pool von gelernten Sprachen die momentan gesprochene Sprache erkennen. Diese Entscheidung kann aufgrund von unterschiedlichen akustischen Räumen oder aufgrund von unterschiedlichen typischen Kombinationen von Phonemen der verschiedenen Sprachen erfolgen. Die Worterkennung dient der Verschriftung der vorliegenden Signale und das Topic Spotting soll mit Hilfe von Schlüsselwörtern eine grobe Charakterisierung des Gesprochenen liefern.
In allen Sprachprojekten des Lehrstuhls ist die sprecherunabhängige Erkennung spontansprachlicher Äußerungen mit großem Wortschatz gefragt, und bei der Bedeutungsanalyse spielen Orts- und Zeitangaben eine zentrale Rolle. Diese weitgehende Übereinstimmung der beiden unterschiedlichen Szenarien Zugauskunft und Terminabsprache in bezug auf die einzusetzenden funktionalen Systemkomponenten bewirkte einen hohen synergetischen Effekt: einerseits waren Problemlösungen wie der Spracherkennungsbaustein, die grammatischen Sprachmodelle, die Module zur prosodischen Etikettierung und zur konzeptuellen Phrasenklassifikation sowie die Dialogkomponente mit vergleichsweise geringem Modifikationsbedarf gleichzeitig in mehreren Anwendungsbereichen nutzbar; andererseits stellt jeder Transfer dieser Art hohe Anforderungen an die Flexibilität einer Analysekomponente und begünstigt so auf lange Sicht die Entwicklung universell verwertbarer Mustererkennungsverfahren.
Die nachstehend aufgelisteten Kernaktivitäten der Sprachverarbeitung belegen diese Einschätzung und werden im weiteren Verlauf dieses Abschnitts noch näher ausgeführt.
Der aus den Arbeiten im Espritprojekt SUNDIAL -- ,,Speech Understanding and Dialogue`` -- hervorgegangene Prototyp eines telefonischen Auskunftssystems für InterCity-Zugverbindungen wurde einem aufwendigen Feldtest unterworfen. Das System kann unter der Nummer +49 9131 16287 angerufen werden. Der Prototyp arbeitet auf einem Arbeitsplatzrechner vom Typ HP735 und besteht -- wie in Bild 9 skizziert -- aus Softwarebausteinen zur Spracherkennung, syntaktisch-semantischen Analyse, Dialogverwaltung und Antwortgenerierung. Die Verbindungsauskünfte werden auf Grundlage des offiziellen deutschen InterCity-Fahrplans erstellt.
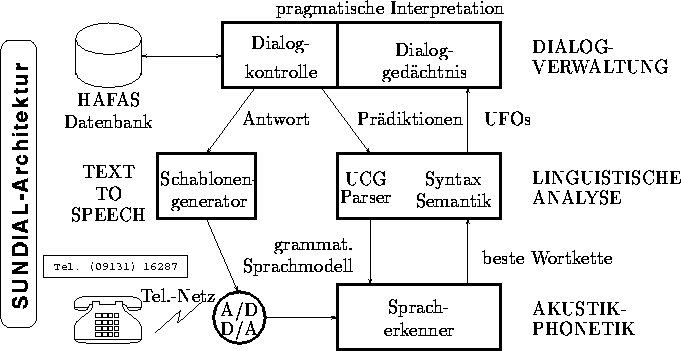
Abbildung 9: Die Architektur des automatischen InterCity-Auskunftssystems
Während des Feldtests wurden mehrere aktualisierte Versionen der Module Worterkenner, Parser und Dialogmanager installiert und evaluiert. Für die Evaluierung mußten die Daten zunächst aufbereitet werden. Dabei wurden offensichtliche Bemühungen von Benutzern, das System lediglich ``aufs Kreuz zu legen'' eliminiert [10]. Die verbleibenden etwa 1000 Dialoge beinhalten etwa 10000 Benutzeräußerungen mit etwa 33000 Wörtern. Alle Äußerungen wurden transliteriert und für alle wurde eine semantische Annotierung durchgeführt, d.h. sowohl die tatsächlich gesprochene Wortfolge als auch eine Beschreibung der Bedeutung des Gesprochenen wurde angefertigt. Weiterhin wurde von einer Person, die an der Entwicklung des Systems nicht beteiligt war, eine Klassifizierung der Dialoge in erfolgreiche und erfolglose Dialoge durchgeführt. Diese Annotierung des Korpus ist mit relativ hohem manuellen Aufwand verbunden, erscheint aber zur Bewertung sowohl der Komponenten als auch des Gesamtsystems notwendig. Bei den in der Literatur veröffentlichten Auswertungen ähnlicher Sprachdialogsysteme wurde bisher noch nicht über einen so hohen Aufwand zur Auswertung berichtet.
Über alle Äußerungen wurde eine Wortakkuratheit von 48,8% erreicht, die semantische Akkuratheit lag mit 49,3% in der gleichen Größenordnung. Trotz dieser relativ schlechten Erkennungsergebnisse wurde der Dialog in 46,9% (also fast der Hälfte) der Fälle erfolgreich abgeschlossen.
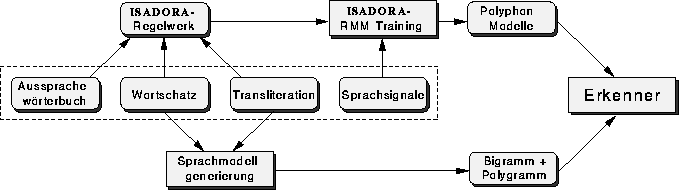
Abbildung: Überblick über die Trainingsphase des Worterkennungssystems
Das Worterkennungssystem des Lehrstuhls kombiniert statistische Lautmodelle, die im Rahmen des ISADORA-Systems [34] trainiert werden, mit statistischen Sprachmodellen (siehe Bild 10). Im Rahmen des DFG-Projekts ``Statistische Modelle für Spontane Sprache'' wurde auf der Grundlage der gesammelten Dialoge an einer Verbesserung der Erkennungsleistung insbesondere durch Berücksichtigung von spontansprachlichen Effekten gearbeitet. Um Äußerungen wie ``Grüß Gott ich möcht' morgen nach --- äh -- nach Würzburg fahren'' zuverlässiger zu erkennen, wurden Häsitationen wie ``äh'' und ``hm'' sowie verschiedene Geräusche in den Wortschatz aufgenommen und in das statistische Sprachmodell integriert. Der Wortschatz wurde zudem von 1110 Wörtern auf insgesamt 1558 Wörter erweitert, indem neue Wörter aus dem Trainingsmaterial hinzugenommen wurden. Durch diese Maßnahmen in Verbindung mit dem zusätzlichen Trainingsmaterial konnte die Wortakkuratheit auf einer als Teststichprobe ausgewählten Teilmenge des gesammelten Sprachmaterials auf 81% gesteigert werden. Trotz des vergrößerten Wortschatzes sind von jeweils 100 gesprochenen Wörtern nach wie vor etwa 3 Wörter nicht im Wortschatz enthalten. Um zu verhindern, daß solche Wörter zu Erkennungsfehlern führen, wurde ein Verfahren entwickelt, solche Wörter als ``unbekannt'' zu erkennen. Eine zukünftige Integration dieses Verfahrens in das Dialogsystem wird die Benutzerfreundlichkeit dadurch steigern, daß das System in Zweifelsfällen nachfragen kann, anstatt unsicher erkannte Äußerungen falsch zu interpretieren.
Die linguistische Analyse bei Verarbeitung gesprochener Sprache stützt sich heutzutage in nahezu allen Fällen auf wissensbasierte Methoden. So ist z.B. im IC-Auskunftssystem EVAR ein wissensbasierter Parser integriert, der die erkannte Benutzeräußerung im Sinne einer Bahnanfrage interpretiert. In den vergangenen Jahren haben sich jedoch die statistischen Methoden vor allem im Bereich der Wort- und Satzerkennung mehr und mehr durchgesetzt und deutlich bessere Resultate erzielt. Daher ist es sinnvoll, auch die Interpretation einer Äußerung mit Hilfe statistischer Methoden und Modelle zu berechnen, so daß eine Systemarchitektur, wie sie in Bild 11 schematisch dargestellt ist, realisiert werden kann.
Setzt man voraus, daß die Bedeutung eines Satzes im Anwendungsbereich durch
eine Folge von semantisch-pragmatischen Konzepten
![]() definiert ist,
so ist es notwendig, die Bayes-Entscheidungsregel auf die in einer
Äußerungskette enthaltenen Konzepte
definiert ist,
so ist es notwendig, die Bayes-Entscheidungsregel auf die in einer
Äußerungskette enthaltenen Konzepte ![]() anzupassen.
Die Interpretation einer Äußerung ist dann bestimmt durch die a posteriori
wahrscheinlichste Konzeptfolge
anzupassen.
Die Interpretation einer Äußerung ist dann bestimmt durch die a posteriori
wahrscheinlichste Konzeptfolge ![]() in einer Wortkette
in einer Wortkette ![]() .
.
Zur Lösung dieser Formel ist es notwendig, statistische Annahmen über die verschiedenen beteiligten Wahrscheinlichkeitsdichtefunktionen zu treffen, sowie über die statistische Abhängigkeit der unterschiedlichen beteiligten Variablen mit einzubeziehen. Anschließend muß ein statistisches Modell ausgewählt werden, welches die Modellierung der Äußerungsinterpretation und die Berechnung der Interpretation effizient ermöglicht.
In [34] sind als erster Ansatz in diese Richtung die konzeptuellen Grammatiken dargestellt, die - unter stark vereinfachenden Annahmen - elementare Bedeutungseinheiten sowie ihre aktuellen Ausprägungen bestimmen sollen.
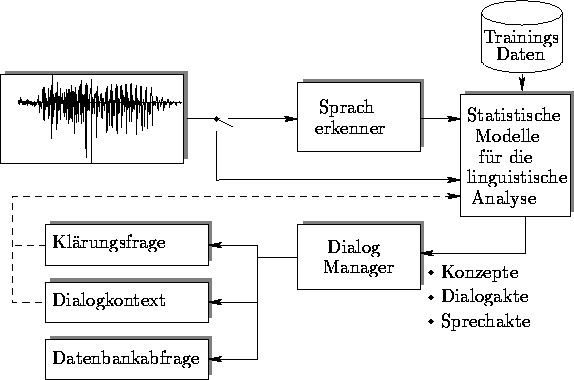
Abbildung 11: Schemadarstellung eines sprachverstehenden Systems mit
statistischen Modellen zur linguistischen Analyse
Langfristiges Ziel des RWC-Projektes ist es, einen integrierten multimodalen Ansatz zur Bild- und Sprachanalyse mit Any-Time-Fähigkeiten und Echtzeitverhalten bereitzustellen. Die zunächst anstehende Aufgabe ist die Entwicklung eines Dialogsystems mit den oben genannten Eigenschaften. Als Grundlagen für die Entwicklung des Dialogsystems dienen der am Lehrstuhl entwickelte parallel iterativ-optimierende Kontrollalgorithmus für die wissensbasierte Musteranalyse [12] und das am Lehrstuhl für den Aufgabenbereich der InterCity-Auskunft entwickelte Dialogsystem EVAR [45]. Bild 12 skizziert die Vorgehensweise der parallelen Instantiierung eines Zielkonzeptes. Ausgehend von der Zuweisung der Worthypothesen an die initialen Knoten (Hypothesenknoten) des Attributflußgraphen werden Instanzen für die Zielkonzepte der Analyse, welche einzelne Dialogschritte modellieren, berechnet.
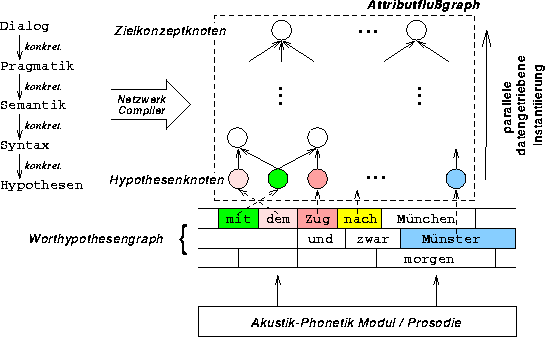
Abbildung 12: Parallele Instantiierung in EVAR
Die linguistische Analyse des Dialogsystems wird mittels eines semantischen Netzwerkformalismus realisiert. Die ursprünglich von dem Formalismus bereitgestellte sequentielle Kontrolle wird in dem neuen System durch den oben genannten parallelen Kontrollalgorithmus ersetzt. Dazu sind Erweiterungen des prozeduralen Wissens der Wissensbasis notwendig, welche im Berichtszeitraum von der Hypothesen-Ebene bis hinauf zur Pragmatik-Ebene durchgeführt wurden. Dies führte zur Bereitstellung eines Systemprototypen, welcher als Resultat der parallelen Analyse eine pragmatische Beschreibung (in Form von instantiierten pragmatischen Konzepten) der eingegangenen Wortkette liefert.
Für eine effiziente Analyse hat sich die Einschränkung des Suchraumes
als notwendig herausgestellt.
Dafür wurde der parallele Kontrollalgorithmus erfolgreich um einen Mechanismus
erweitert,
welcher die in der Wissensbasis von EVAR definierten Restriktionen (bezüglich
Attributwerte, Modalitäten von Konzepten, etc.) propagiert und während der
Analyse berücksichtigt.
Statische Restriktionen,
welche nur von dem linguistischen und
aufgabespezifischen Wissen abhängig sind, werden in einem
Analysevorbereitungsschritt propagiert.
Dabei werden die Knoten aus dem von der parallelen Kontrolle
verwendeten Attributflußgraphen gelöscht, welche für eine korrekte Analyse
ausgeschlossen werden können.
Durch die anwendungsabhängige Minimierung des Attributflußgraphen konnte die
Zeit für einen Iterationsschritt
um den Faktor 6,5 verkürzt werden.
Zusätzlich wurde der durch linguistische Ambiguitäten
entstehende Suchraum zur Instantiierung eines pragmatischen Konzeptes von
![]() auf
auf ![]() reduziert, was zu
einer ersten bedeutenden
Verringerung der Zeit für den gesamten Analyseprozeß führte.
Dynamische
Restriktionen, welche von der zu analysierenden Wortkette abhängig sind, werden
top-down zwischen zwei Iterationsschritten propagiert.
Dafür wurde die Instantiierung
obligatorischer und optionaler Konzepte getrennt: nach der Berechnung aller
zu obligatorischen Konzepten gehörenden Knoten des Attributflußgraphen
werden in einem top-down Schritt anfallende Restriktionen an die entsprechenden zu
optionalen Konzepten gehörenden Knoten propagiert. Die optionalen Konzepte werden
dann unter Berücksichtigung dieser Restriktionen instantiiert,
wodurch sich der Suchraum bzgl. der konkurrierenden Hypothesen
bedeutend reduziert.
Künftige Arbeiten
in diesem Projekt
beschäftigen sich mit der Auswertung des implementierten
Prototypen und mit der Erweiterung des Systems auf Dialogebene.
reduziert, was zu
einer ersten bedeutenden
Verringerung der Zeit für den gesamten Analyseprozeß führte.
Dynamische
Restriktionen, welche von der zu analysierenden Wortkette abhängig sind, werden
top-down zwischen zwei Iterationsschritten propagiert.
Dafür wurde die Instantiierung
obligatorischer und optionaler Konzepte getrennt: nach der Berechnung aller
zu obligatorischen Konzepten gehörenden Knoten des Attributflußgraphen
werden in einem top-down Schritt anfallende Restriktionen an die entsprechenden zu
optionalen Konzepten gehörenden Knoten propagiert. Die optionalen Konzepte werden
dann unter Berücksichtigung dieser Restriktionen instantiiert,
wodurch sich der Suchraum bzgl. der konkurrierenden Hypothesen
bedeutend reduziert.
Künftige Arbeiten
in diesem Projekt
beschäftigen sich mit der Auswertung des implementierten
Prototypen und mit der Erweiterung des Systems auf Dialogebene.
Die Aktivitäten im Rahmen der Prosodie, die sich mit lautübergreifenden sprachlichen Eigenschaften (wie z.B. Betonung, intonatorische Markierung des Satzmodus oder Gliederung in prosodische Phrasen) beschäftigt, wurden im letzten Jahr von dem bisher untersuchten, gelesenen ERBA-Korpus (vgl. [3]) auf das spontansprachliche VERBMOBIL-Szenario (automatische Übersetzung von gesprochenen Verhandlungsdialogen) übertragen.
In der gesprochenen Sprache übernimmt die Prosodie die strukturierende Rolle der
Interpunktion in der Schriftsprache.
Ähnlich, wie durch die Interpunktionszeichen in der Schrift
nicht nur die Übersichtlichkeit erhöht sondern oft sogar der Sinn eines Satzes erst
eindeutig festgelegt wird, führt die prosodische Strukturierung einer sprachlichen
Äußerung durch die Auflösung syntaktischer Ambiguitäten zu einer eindeutigen
Interpretation.
In folgendem typischen Beispiel aus dem VERBMOBIL-Korpus
(vgl. auch [23])
sollen die vertikalen Linien
mögliche Satzgrenzen darstellen:
In der Schriftsprache können diese Linien zum Teil durch Komma, Punkt oder Fragezeichen ersetzt werden; es gibt mindestens 36 unterschiedliche, syntaktisch korrekte Alternativen. Die folgenden Beispiele zeigen zwei dieser Möglichkeiten zusammen mit den entsprechenden Übersetzungen ins Englische:

Genauso wichtig wie die Auflösung syntaktischer Ambiguitäten ist die Erkennung von Akzentuierungen für eine adäquate automatische Übersetzung. Im folgenden Beispiel besitzt das Wort noch abhängig davon, ob es akzentuiert ist oder nicht, zwei verschiedene Funktionen und der Satz somit zwei unterschiedliche Interpretationen mit zwei Übersetzungsvarianten:

Die Grundlage für Experimente zur Grenzen- bzw.\ Akzentuierungserkennung bildeten insgesamt 33 von der TU Braunschweig prosodisch etikettierte VERBMOBIL-Dialoge (66 Sprecher, 112Minuten Sprache). Davon wurden 30 Dialoge als Trainingsstichprobe, die restlichen 3 Dialoge als Teststichprobe gewählt. Jedem Wort in diesem Korpus ist ein Etikett zugeordnet, das zum einen Auskunft darüber gibt, ob dieses Wort akzentuiert oder nicht-akzentuiert ist, und zum anderen ob dieses Wort unmittelbar einer Phrasengrenze vorangeht (wobei unterschiedliche Typen von Grenzen unterschieden werden). Bei der Merkmalextraktion werden die Wort-, Silben- und Lautpositionen automatisch mit Hilfe eines Worterkenners ermittelt. Darauf aufbauend wird für jede Silbe ein Merkmalvektor berechnet (siehe auch [1]), der die prosodischen Eigenschaften wie Dauer, Pausensetzung, und Energie- bzw. Tonhöhenverlauf (zu letzterem siehe auch [14]) dieser Silbe sowie einiger benachbarter Silben charakterisiert. Die Vorgehensweise bei der Extraktion prosodischer Merkmale ist in Bild 13 illustriert.
Als Klassifikatoren wurden unterschiedliche neuronale Netze verwendet. Bei der Klassifikation akzentuierter vs. nicht-akzentuierter Wörter konnte bisher eine Erkennungsrate von 83% erzielt werden. Für das 2-Klassenproblem ``Grenze'' vs. ``Nicht-Grenze'' betrug die beste Erkennungsrate 86%.
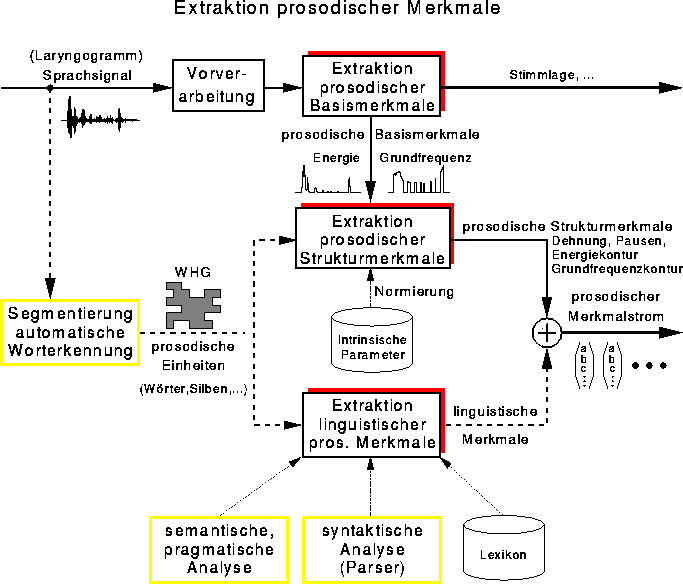
Abbildung: Schematischer Überblick über die Extraktion
prosodischer Merkmale
Die automatische prosodische Satzgrenzenerkennung wurde in den VERBMOBIL-Forschungsprototypen folgendermassen integriert: Bei gesprochener Sprache arbeitet die Worterkennung beim derzeitigen Stand der Technik nicht fehlerfrei. Aus diesem Grunde werden üblicherweise alternative Worthypothesen generiert, deren zeitliche Aufeinanderfolge sich aus einem Graphen ergibt. Aufgabe der Syntaxanalyse ist, die in einem solchen Worthypothesengraphen optimale Wortkette zu finden, welche mit einer gegebenen Grammatik konsistent ist. Das Prosodiemodul annotiert jede Kante in diesem Wortgraphen mit einer Wahrscheinlichkeit für das Vorhandensein einer Satzgrenze nach dem zugehörigen Wort [23]. Diese Wahrscheinlichkeiten werden mit den akustischen Wortbewertungen und linguistischen Bewertungen bei der Suche nach der optimalen Wortkette verknüpft. Vorläufige Untersuchungen auf einer kleinen Stichprobe zeigten, daß sich sowohl die Suchzeit als auch die Zahl der alternativen Ableitungsbäume um bis zu 80% reduzieren lassen. Der Forschungsprototyp ist weltweit das erste voll funktionsfähige sprachverstehende System, das prosodische Information in dieser Form erfolgreich verwendet. Es wurde bislang mehrfach der Öffentlichkeit auf Pressekonferenzen und Messen vorgeführt. Bild 14 zeigt die Architektur des VERBMOBIL-Gesamtsystems. Die durchgezogenen Pfeile, welche aus dem Prosodie-Modul herausführen, zeigen auf Module, die z.Zt. auf prosodische Information zugreifen. Die gestrichelten Linien zeigen auf Module, bei denen der Einsatz prosodischer Information geplant ist.
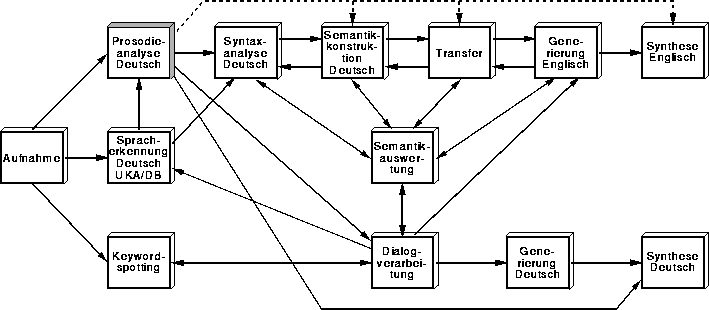
Abbildung: Architektur des VERBMOBIL-Gesamtsystems
Da VERBMOBIL nur dann aktiviert wird, wenn ein Dialogpartner den Dialog nicht in der Fremdsprache Englisch weiterführen kann, gibt es dazwischen Phasen, in denen VERBMOBIL inaktiv ist, d.h. es wird keine Übersetzung benötigt. Viele Äußerungen sind nur im Dialogkontext vollständig zu verstehen, d.h. auch in inaktiven Phasen muß der Dialogkontext aktualisiert werden, was durch eine grobe Dialogverfolgung möglich ist.
In VERBMOBIL dienen Dialogakte (siehe [20]) zum einen als Transfereinheiten der gesprochenen Sprache. Zum anderen werden sie als elementare Einheiten zur Planerkennung eingesetzt. Dialogakte sind verankert in einem Handlungsschema. Zu jedem Dialogzeitpunkt gibt das Dialogmodell (siehe Bild 15) an, welche Dialogakte wechselseitig folgen können.
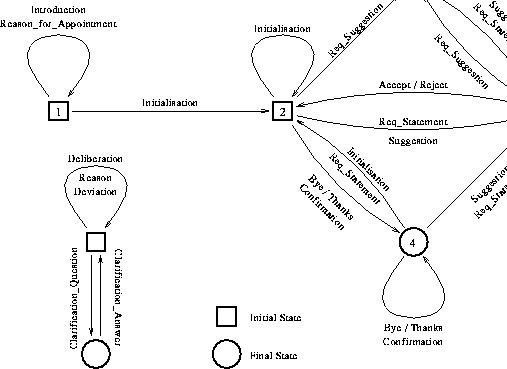
Abbildung 15: Das Dialog Modell in VERBMOBIL
Mit Hilfe von Keyword-Spotting werden die Äußerungen in inaktiven Phasen analysiert und daraus gewonnene Ergebnisse eingesetzt, um die Pläne des Benutzers zu verfolgen. Der Keyword-Spotter benutzt dazu Listen von Schlüsselwörtern, die für bestimmte Dialogakte charakteristisch sind. Diese Schlüsselwörter wurden aus einer Korpusanalyse und mit einem automatischen Verfahren -- semantischen Klassifikationsbäumen -- gewonnen [27].
Klassifikationsbäume sind Entscheidungsbäume zur Klassifikation von Mustern, wobei die Entscheidungen anhand von Regeln getroffen werden. Die spezifischen Regeln für eine gegebene Aufgabe und die Reihenfolge der Anwendung dieser Regeln werden jedoch, im Gegensatz zu konventionellen regelbasierten Systemen, automatisch anhand einer Stichprobe trainiert. Die Struktur eines binären Klassifikationsbaumes sieht prinzipiell folgendermaßen aus: An jedem nichtterminalen Knoten wird eine binäre Aufspaltungsregel angewendet, so daß jeder dieser Knoten genau zwei Tochterknoten hat. Die terminalen Knoten im Baum werden mit einer Klasse und/oder mit einem Bewertungsvektor markiert. Die binären Aufspaltungsregeln werden generell durch JA/NEIN Fragen dargestellt. Semantische Klassifikationsbäume verarbeiten allgemein die in einer Symbolkette gegebene textuelle Information. Die Fragen an den Knoten eines semantischen Klassifikationsbaumes beziehen sich auf `Schlüsselwörter', welche während der Trainingsphase automatisch aus dem gegebenen Vokabular selektiert werden.